À l’ère où l’intelligence artificielle s’infiltre de plus en plus dans les rouages des réseaux sociaux, des plateformes majeures telles qu’Instagram, Facebook, LinkedIn et X collectent et exploitent les données personnelles des utilisateurs pour entraîner leurs modèles. Cette utilisation parfois opaque soulève de fortes inquiétudes quant à la protection des données. En 2025, Meta avec ses services, LinkedIn sous l’égide de Microsoft, ou encore X, anciennement Twitter, ont intégré l’entraînement IA comme fonctionnalité clé, souvent sans solliciter explicitement l’accord des utilisateurs. Pourtant, il demeure possible de reprendre la main. En modulant quelques paramètres bien dissimulés dans ces plateformes, chaque internaute peut s’opposer à ce que ses publications, photos ou interactions servent à développer des intelligences artificielles. Ce guide pratique vous explique étape par étape comment explorer ces réglages afin de préserver votre vie privée et sécuriser vos données personnelles face à l’inexorable avancée des IA dans le paysage numérique.
Empêcher l’entraînement de l’intelligence artificielle sur Meta : Facebook et Instagram
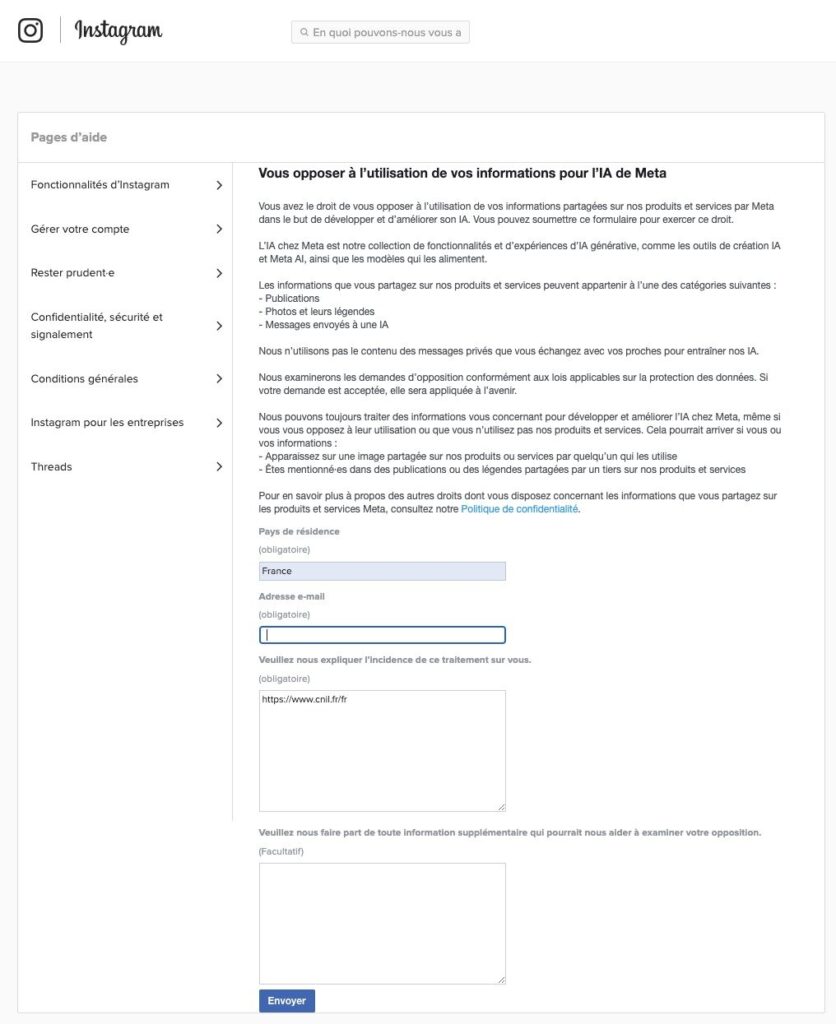
Meta, l’un des géants des réseaux sociaux, utilise désormais les contenus publics de Facebook, Instagram ou encore WhatsApp pour améliorer ses systèmes d’intelligence artificielle. Cette transformation, effective depuis mai 2025, est source de vigilance accrue pour les utilisateurs européens. Pour conserver le contrôle sur ses données, il suffit d’un refus clair et unique, valable sur l’ensemble des services Meta.
Sur Instagram, la démarche se fait depuis l’application mobile ou la version web en accédant aux paramètres, puis au « Centre de confidentialité ». Le lien « Opposer » permet d’indiquer expressément son rejet, ce qui empêche Meta d’utiliser ses photos, commentaires ou publications pour entraîner ses IA. Cette même opération est à répéter depuis Facebook, ou plus simplement via un lien direct proposé par la plateforme. Ce refus n’affecte aucunement l’usage classique du réseau social, mais agit uniquement sur le dispositif d’agrégation de données pour l’IA.
Cette mesure est une illustration parfaite de la nécessité de rester proactif face à la collecte intrusive de données, surtout quand la finalité dépasse le simple partage social pour s’étendre à des usages algorithmiques complexes.

Les réglages clés pour bloquer l’exploitation des données sur LinkedIn et Microsoft
LinkedIn, réseau professionnel détenu par Microsoft, fait également partie des plateformes où les données servent désormais à entraîner des modèles d’intelligence artificielle. Contrairement à Meta, LinkedIn propose un accès plus direct à la gestion de cette fonctionnalité via son interface utilisateur. L’utilisateur doit cliquer sur sa photo de profil, aller dans « Préférences et confidentialité », puis dans l’onglet confidentialité des données, où il peut désactiver explicitement l’option relative à l’utilisation de ses données dans l’amélioration de l’IA générative.
Ce paramètre, bien que simple à atteindre, est encore méconnu du plus grand nombre, et révèle combien la protection des données personnelles sur les réseaux sociaux demeure un chantier délicat et souvent ignoré du public. Limiter l’usage de ces informations est essentiel non seulement pour la vie privée, mais aussi pour protéger sa réputation en ligne, un enjeu sur lequel Microsoft insiste dans ses politiques.
Comment X (ex-Twitter) récolte vos données pour Grok et comment s’en prémunir
Depuis sa reprise par Elon Musk et la transformation en X, la plateforme poursuit une intégration profonde de l’intelligence artificielle à travers son chatbot Grok. Afin d’optimiser Grok, X exploite les données publiques, interactions et recherches des utilisateurs. Pourtant, l’entreprise offre une option de désactivation bien que peu visible dans les paramètres.
Pour désactiver cette collecte, il faut naviguer depuis la version web vers le menu « Paramètres et confidentialité », puis « Confidentialité et sécurité », et enfin dans la section dédiée à Grok. Il suffit alors de décocher la case autorisant l’usage des données pour l’entraînement et l’ajustement de l’IA. Cette action évite non seulement l’exploitation des données personnelles, mais réduit aussi la participation involontaire à la construction d’outils d’intelligence artificielle peu transparents.
Protéger ses données contre le partage avec des tiers sur Tumblr
Moins évoqué, Tumblr reste une plateforme où la question du partage de données à des tiers pour entraîner des intelligences artificielles est bien réelle. Par défaut, le réseau facilite ce partage, mais les utilisateurs peuvent s’opposer à cet usage.
Pour ce faire, il faut aller dans les paramètres du blog, puis dans la section visibilité, cocher la case qui empêche le partage avec des tiers. Cette précaution, bien que simple, est rarement mise en œuvre, et souligne l’importance de vérifier les paramètres même sur des plateformes considérées comme secondaires ou moins mainstream.
Les enjeux élargis de la protection des données face à l’intelligence artificielle
Au-delà des simples réglages, la question du consentement et de la transparence dans l’usage des données sur les réseaux sociaux demeure un défi majeur pour 2025. Alors que Meta, Microsoft, et d’autres leaders technologiques multiplient les initiatives en intelligence artificielle, les utilisateurs ont à défendre leur droit fondamental à la vie privée. Cela comprend non seulement le choix de refuser le partage de leurs données, mais aussi la sensibilisation à la manière dont ces technologies transforment le paysage digital.
Une stratégie efficace passe notamment par l’éducation aux outils numériques, comme en témoignent certains articles détaillés sur les solutions de gestion de données ou les meilleures pratiques en no-code et marketing digital. Ces ressources aident à comprendre comment s’adapter à cet environnement où l’IA et la protection des données s’entremêlent, parfois de façon contradictoire. Pour approfondir, de nombreuses plateformes comme TasksGenius proposent des guides complets sur la maîtrise de ses données, notamment comment faire du no-code ou les starter packs IA, facilitant ainsi la navigation dans cet univers complexe.